Training an Agent with Reinforcement Learning
Introduction
This blog post will detail the process and learnings of fine-tuning a model used as part of an agentic system, via reinforcement learning (RL). The model will be trained to use the tools to answer natural language questions over a Github repo, for example: "What function do I need to call to do X in repo Y?". Motivation for this task came from my own experience evaluating customer support agents at my day job, all of which do retrieval augmented generation (RAG) over some corpora of data (e.g. Slack, email, Notion), but none supported Github as a corpus (at the time of writing), which at a software company is quite limiting. So I thought this task could be both relevant and useful.
The model and dataset can be found on Huggingface. The code is available on Github.
This post draws inspiration from, and heavily credits the work done in this blog post by OpenPipe. ART was used which made the training process very smooth.
Note: this post does not claim to do things in the most optimal way, and rather focuses on my own learnings and design choices.
Why Reinforcement Learning?
RL is about trial and error, making it a natural fit for training tool-use, as opposed to supervised training. Through RL, we will train the model to use the tools that initially are unfamiliar to work with, yielding a model that is specialised for our use case. RL is the easiest lever you have to train models for agentic tasks, with the alternative being inference-time scaling for example.
The Task
The task of the agent is as follows: given a natural language question about a repo, use agentic RAG (to reduce hallucinations and ground answers) to provide a response that clearly and accurately describes the code to answer the question. Agentic RAG is a more intelligent method, as opposed to naive RAG which at a high level does:
- Get an embedding representation of the prompt.
- Do similarity search, e.g. via dot product against chunk embeddings in vector DB.
- Return similar chunks and enrich context by appending to prompt.
Whereas agentic RAG, similar to how a human does search (iteratively and adaptively), will do it multi-turn, be able to refine the search, and have the ability to explore new search paths based on returned results.
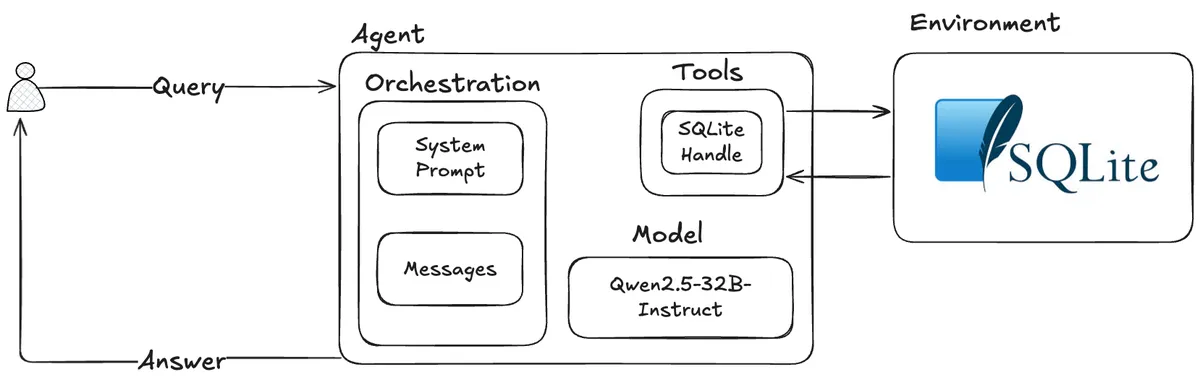
Architecture
Model
We need a model with strong enough priors that include instruction following, coding capabilities, multi-turn behaviour, and tool use. Qwen2.5-32B-Instruct has these priors and was chosen for the following reasons:
- Qwen uses an Apache 2.0 license, which allows for general availability of the fine-tuned variant.
- Qwen models are generally very good.
- Compatible with vLLM and Unsloth.
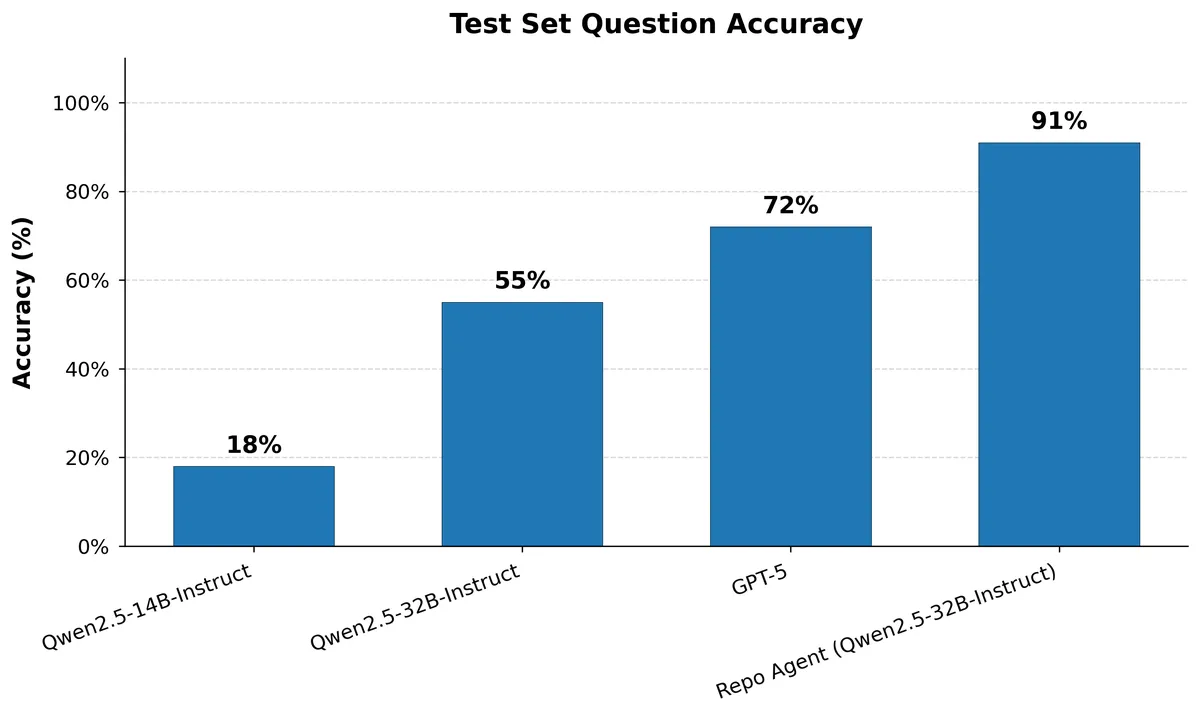
- Smaller variants in the Qwen2.5 model family (7B and 14B Instruct) had benchmarks scores that were < 20%, which is signal that the task is too hard, and training the model via RL would be difficult (14B . The 32B variant scored 50%, which is a good signal the model will be able to learn the task.
- Supported and recommended by OpenPipe for training using ART.
Supervised fine-tuning (SFT) is a powerful tool to maximise the performance of the model before RL fine-tuning. This potentially could've been done to the 14B model making it suitable for RL. The workflow for doing this assumes that your evals, tools and environment are set up well and would be as follows:
- Take an API model that performs well on the benchmarks, e.g. GPT-5
- Generate a dataset where X = prompt, Y = completion which is the agent trace.
- Take smaller local model, do SFT where the objective is to increase likelihood of generating the response, Y.
- Benchmark and save fine-tuned variant ready for RL.
Environment and Tools
The environment for the agent will be an SQLite database. The API for interacting with the database will be an SQLite connection, with abstractions on top of this connection forming the tools the agent will call to interact with its environment.
The 2 tools used by the agent to interact with the database are:
- search_repo: Search a repo for functions by keywords.
- read_repo_function: Read the full details of a function from a repo.
These tools are used for the retrieval of context, and use the fts5 SQLite extension to do full-text search. This approach was selected over embedding-similarity search due its simplicity (don't need embedding model or have to worry about chunking strategies) and strong performance. The tools use sensible defaults to manage context pressure (I found that the vLLM server would timeout if the context grew too large during rollouts), like only returning the first 10 functions of a repo.
The ergonomics of your tools and the agents experience using them, is critical. Your tools will end up as prompts to the LLM, and as you would engineer a well-defined prompt, you should do the same with your tools. Similarly as software engineers would appreciate well documented, structured, self-intuitive and clean code, an LLM would too. I think of this as Developer Experience but for agents. This is an low-hanging fruit for agent performance. Some examples of things you can do include:
- Write good doc strings: describe the function, inputs, return values, and show an example usage.
- Use intuitive names: for both functions and parameters, so the model can infer meaning.
- Clean code: keep logic clear and easy to follow. E.g. avoiding large amounts of if-statements.
The Agentic Loop
The agentic loop is a programmatic loop with an exit condition (e.g. max iterations or an error), that drives the agent to its goal. The code for the loop can be found here. The loop executes the following steps:
- Initialize the conversation with the system prompt, that includes tool definitions and schemas using Pydantic.
- Request a completion from the LLM.
- Parse completion, mapping token space to code space and extract tool calls.
- Execute tool call and capture response.
- Append completion and tool call result to conversation.
- Repeat for max turns or till an answer is found.
The agentic loop used had the following exit conditions:
- The agent found an answer and called the return_answer tool.
- No tool calls were contained in the LLM response.
- Exceptions raised from decoding errors or tool call errors.
- 10 turns were exhausted.
A limitation of this loop is that it doesn't handle the classes of exceptions explicitly. For example, if the exception for a completion request is a 429 rate-limit error, the agent could retry the request after a delay.
Data Generation
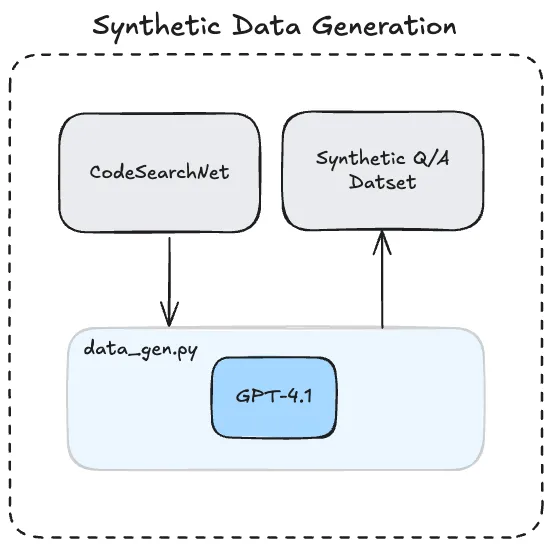
A synthetic data set comprised of question/answer pairs derived from the CodeSearchNet dataset was generated using GPT-4.1 (system prompt). The data set can be found on Huggingface, containing ~2.3k training samples and 1k test samples. Synthetic data samples were intended to reflect realistic questions asked by a human that were moderately difficult, this meant questions reference at most 3 functions (e.g. describing a workflow using class methods). 3 functions were selected based on benchmarking, targeting an appropriate difficulty. The sample also included reference functions for grounding and a score on how realistic the question was, this can be used for quality filtering.
This step was an iterative process, which involved managing the difficulty and semantics of the question through system prompt tuning. For example, questions like "How do I read a file", were too general and easy for the agent, causing it to rely on it's prior knowledge as opposed to using the tools. Appending phrases like "In this library/repo" also helped narrow the scope for the agent. It was also important to not include the reference functions in the question; when the functions were included, the agent would often just recite the functions in the answer and the LLM as a judge would mark the question correctly, despite the generated answer differing semantically from the reference answer, which is a form of reward hacking. It's critical to ensure your evals are resilient to reward hacking, this was done by manual inspection of completions.
Below is an example Q/A pair:
Question:
"If I want to asynchronously send a signal to all receivers filtered by sender, which functions should I use in this codebase?"
Answer:
"Call Signal.send(sender, **kwargs) to dispatch the signal. Internally, it uses Signal._get_receivers(sender) to filter the matching receivers for the provided sender."
Repo:
"475Cumulus/TBone"
Functions:
["Signal.send", "Signal._get_receivers"]
How Realistic:
"0.92"
Training
The E2E training pipeline involved both local and remote development phases and is summarised below:
Local
- Benchmark models, to find model suitable for fine-tuning. This involved running benchmarks over the Qwen2.5 family, starting at 7B and increasing to 32B. Iterations on the data generation was also done here to adjust difficulty (e.g. reducing the maximum number of functions in a question to 3).
- Continue evaluating performance of model from 1. In this phase tools were refined and the system prompt was tuned to maximise the performance of the model before training. You also do not want to do tool debugging during training.
Remote
- Begin fine-tuning using ART remotely. A section below will detail this training loop.
- Benchmark trained model against testing data.
- Repeat until satisfactory test results (refining tools, hyper pameters etc.)
I experienced teething issues in the remote development loop such as vLLM crashes due to timeouts and unexpected ssh connection closes. I found these tools to be critical for this phase:
- rsync for pushing and pulling files between local and remote.
- tmux for creating persistent sessions that I could reattach in the case the ssh connection closed.
- lsof and nvtop for observability into GPU usage and the vLLM instance.
- uv for making dependency management a breeze.
- Weights and Biases for observability, providing metrics and logging, essential for visibility into the training runs.
Reinforcement Learning Setup
The model was fine-tuned using the GRPO RL algorithm. This is the algorithm that ART uses and is a form of PPO. At a high level GRPO does:
- Generate a batch (in our case 4 per prompt) of completions per prompt and score them using a reward function (an LLM as a judge was used).
- Calculate the group advantage, which is looking at how well each completion did relative to one another.
- Get the per-token advantage, which is done by getting the token probabilities from a forward pass.
- Increase the probability of generating those tokens which resulted in a higher reward and decrease the probabilities of those that resulted in a lower reward.
- But also don't change the model too much, which is enforced through KL divergence. This is a form a regularisation that keeps the model in the same behavioural space, targeting small surgical changes that improve the model.
The reward function used was an LLM as a judge, as the verification of the answer isn't objectively verifiable. System prompt here. Gemini 2.5 Flash was used as the judge LLM. Gemini was selected to avoid having the synthetic generation LLM and the judge LLM being from the same family to avoid bias.
Having strong evals formed by reward functions is critical for observability, understanding, and measuring your system. You can then create a feedback loop using these evals for system prompt tuning and tool use, having confidence that your agent is improving. This feedback loop was critical for the local training phase.
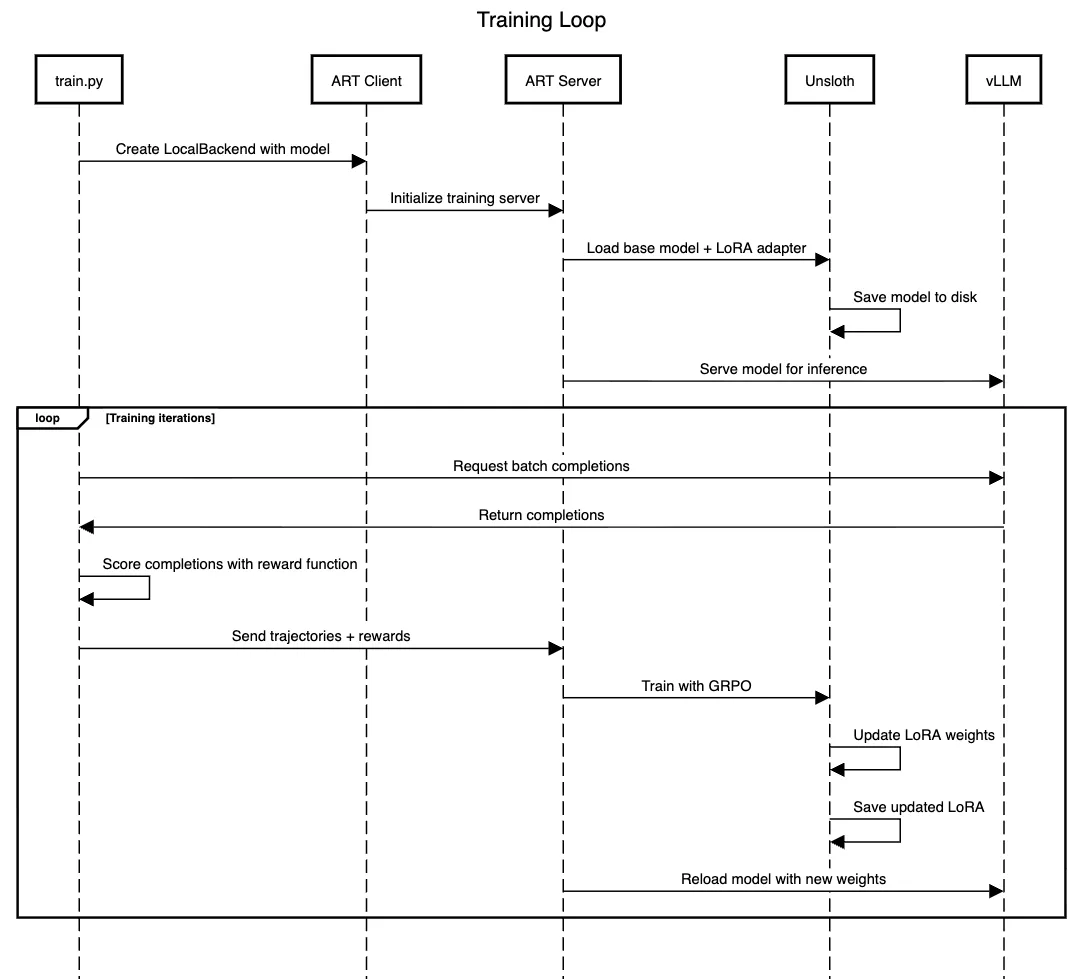
Training Loop
ART is a powerful training harness that manages a Unsloth and vLLM instance under the hood. Unsloth supports LoRA (Low-Rank Adaptation) adapters which train a much smaller proportion of model weights, drastically reducing the resource requirements (training memory and disk) for training, allowing for frequent checkpointing. LoRA is a suitable choice, as this agent is doing one task that is specific and narrow. If the goal of the agent was to be much more general and multi-task, LoRA might not be the right choice (as LoRA bounds the amount the model can learn). vLLM is an efficient serving engine for inference offering strong throughput, efficient memory management (uses PagedAttention to manage KV cache), and batch completions. The training loop using ART is summarised in the sequence diagram below.
Results
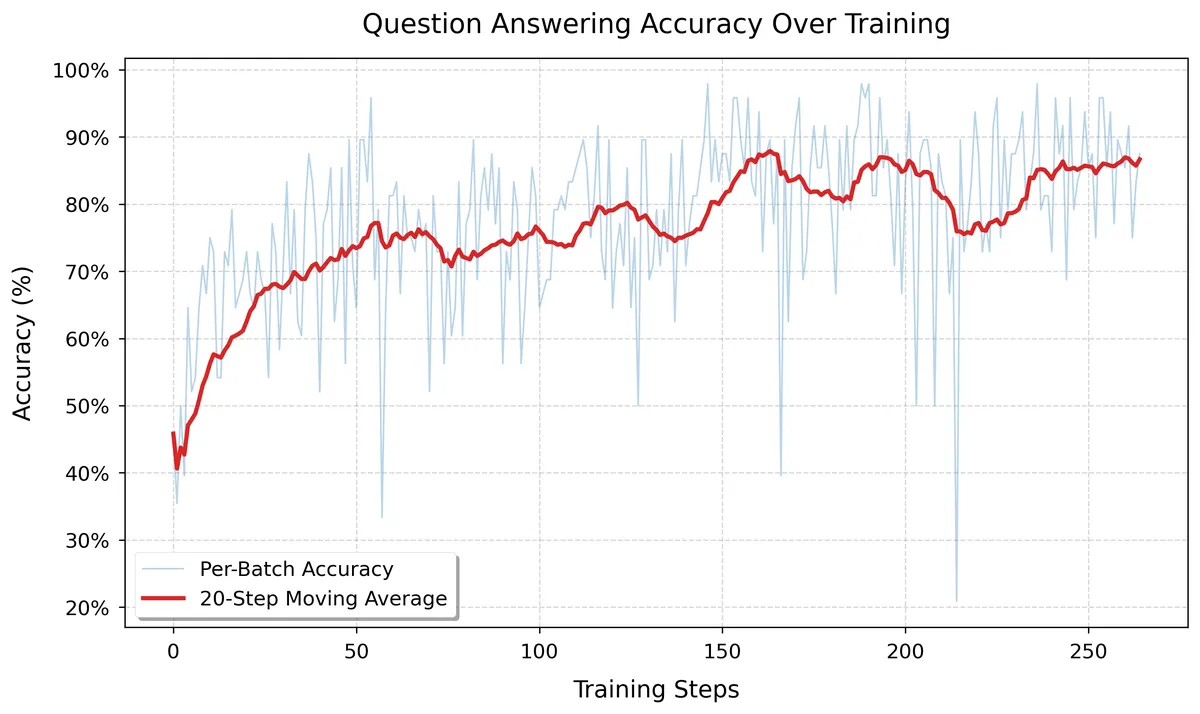
The model was trained for 2 epochs with a learning rate of 1.2e-5. Rollouts consisted of 4 completions per prompt and a batch size of 12 questions, resulting in a batch size of 48 for gradient updates (these hyper parameters were taken from https://openpipe.ai/blog/art-e-mail-agent). The model was trained on cluster using a H100 for 2 days which roughly at the time of writing costs ~$90. The training results are shown in the graph below, where the model achieved an average of 86% of questions answered correctly in a batch at training step 264 on the training set. The model likely could've been trained for longer, but was chosen not to for costs.
Conclusion and Future Improvements
RL is an incredibly powerful tool for training models with complex reward signals, that wouldn't be possible through SFT. Its application to fine-tuning smaller models for agentic tasks is very effective, beating the performance of much larger SoTA models like GPT-5 (you win on cost and latency). The deployment of these smaller task-specific RL fine-tuned models will be powerful paradigm going forward (see this tweet). The success of this project wouldn't have been possible without ART. It applies strong and meaningful abstractions lowering the barrier of entry for RL fine-tuning.
This system is by no means production ready, there is weak durability (no persistence of turns nor handling of unclean shutdowns) and lack of robustness (no intelligent handling of exceptions, failed tool calls ect) to name a few. There is also performance gains left on the table here. More reward signals could be added like crediting the functions referenced, reducing tool call counts (ART-E does this), and training for more steps or epochs. However, this result is satisfactory given the main goal here was learning.